Multimodal and Multi-view Models for Emotion Recognition - Part I
NOTE: here are the links of the paper and ACL presentation video

I had the great opportunity to do my first internship in the US at Amazon; I worked at the Alexa Speech team in Boston over the summer in 2018. This post describes in a more friendly way the work my co-authors and I did for emotion recognition using acoustics and language coming from speech.
The paper covers two main sections:
- Multimodal fusion: we propose to fuse acoustic and text modalities at the word level
- Multi-view learning: we induce semantics into acoustic-only models
This post covers the multimodal fusion part. I will add the multi-view learning part in another post.
Introduction
You can get two important conversational aspects from speech: how things are said, and what is being said. The first one corresponds to acoustic information, where things like pitch and arousal are captured. The second one refers to linguistic information, which focuses on the semantics and thoughts that the speaker wants to convey.
These two aspects are complementary, and we use both of them in our daily conversation to communicate effectively. For example, consider the phrase “oh my gosh,” by only looking at the text/language, would you be able to tell the emotion behind it? Probably you would be ambivalent in between choosing sadness or happiness, but things become clearer when you add acoustic information to it:
From the audio/acoustics, you can clear up things and guess that the emotion is most likely happiness.
Similarly, you can imagine cases where acoustics by itself (think of a uniform and constant tone
from someone’s voice) is not sufficient to tell the emotion and thus you have to look into the
semantics to make a decision.
Okay, okay… got it! Now tell me how to combine modalities 
At the point of the paper publication, people had been combining modalities at the utterance level. That is, they process each modality independently to get separate representation for the entire utterance, and then such representations are fused (e.g., concatenated) into a single one. Although this works pretty well in practice, it is not really how both modalities occur. Acoustics and semantics are naturally emmitted and perceived together, and we, as humans, understand both of them mainly at the word level. So it makes sense to fuse modalities at every word instead of at the utterance level. And that’s what we did in this paper.
Here’s an illustration of the alignment between the audio frames and the corresponding transcripts:
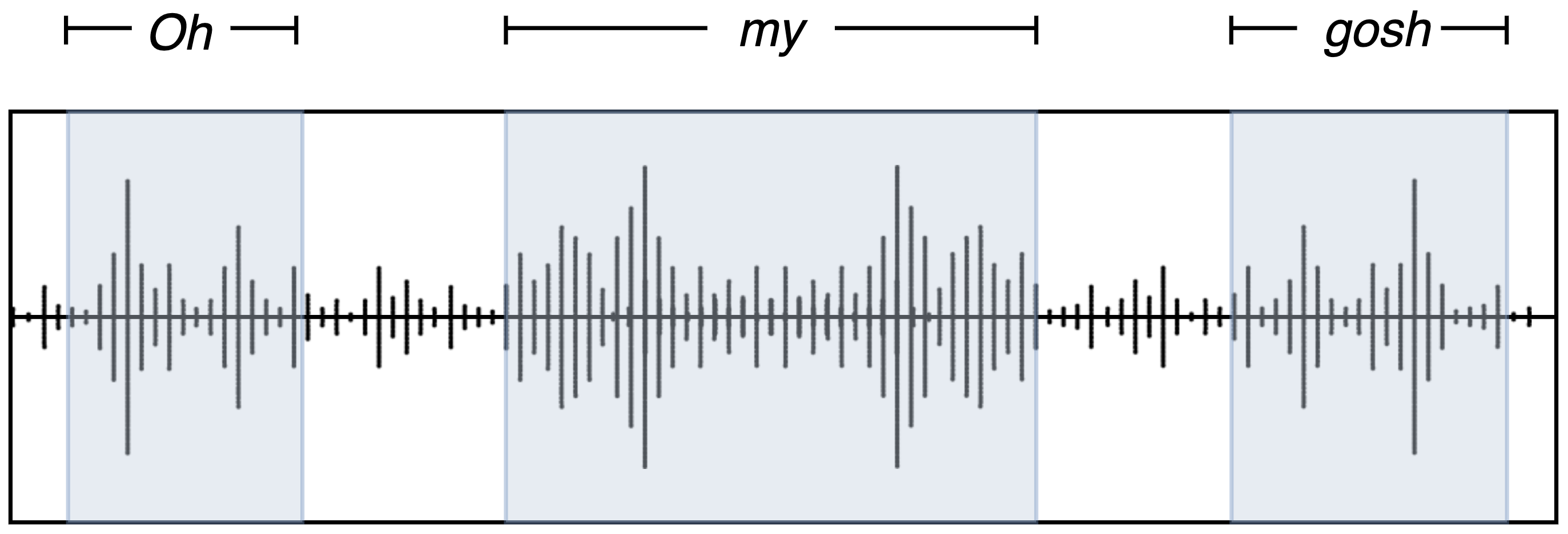
Aligning modalities
We use the USC-IEMOCAP dataset in the paper, which provides audios and the corresponding transcripts of multiple conversations between two people (check their website for more details). Each word in the transcripts has the starting and ending frame numbers. This allows us to focus on the chunks of frames where the words occur along the audio.
Now one can think of concatenating acoustic features and text at the word level because we know what are the corresponding frames for every word, but we have a dimnesionality incompatibility here. For every word in the utterance, we have a sequence of frame features. This incompatibility is what led us to introduce acoustic word representations. We process the sequence of acoustic features using a bidirectional LSTM and choose the hidden states of the timesteps determined by the word boundaries. This provides two vectors, one per direction, which we concatenate into a single one:
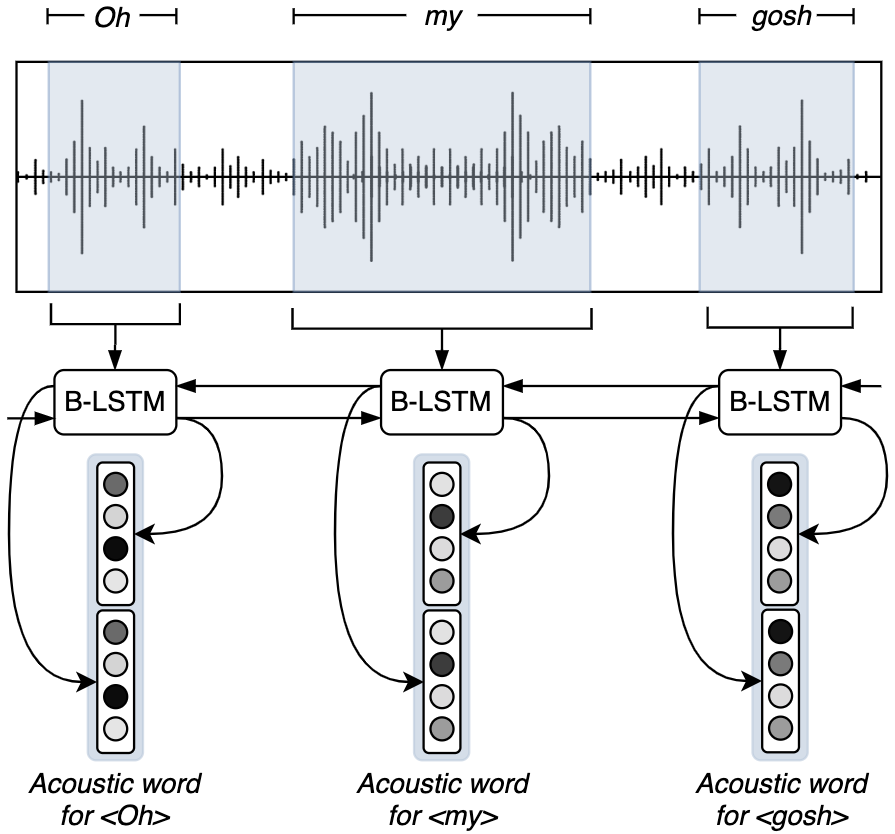
Fusing modalities
With this acoustic word representation, now we can fuse modalities at the word level. The fusion can simply be a concatenation of the vectors from the modalities, but sometimes one modality is more informative than the other, just like in the examples at the beggining of this post. That said, we let the model learn when to pay more attention to one or the other using the GMU cell [1]. In this case, we use the bimodal version since we are only dealing with text and audio:
| $$ \begin{aligned} h_a &= \mathrm{tanh}(\mathrm{W}_a x_a + b_a) \\ h_t &= \mathrm{tanh}(\mathrm{W}_t x_t + b_t) \\ z &= \sigma(\mathrm{W}_z [x_a, x_t] + b_z) \\ h &= z * h_a + (1 - z) * h_t \end{aligned} $$ |
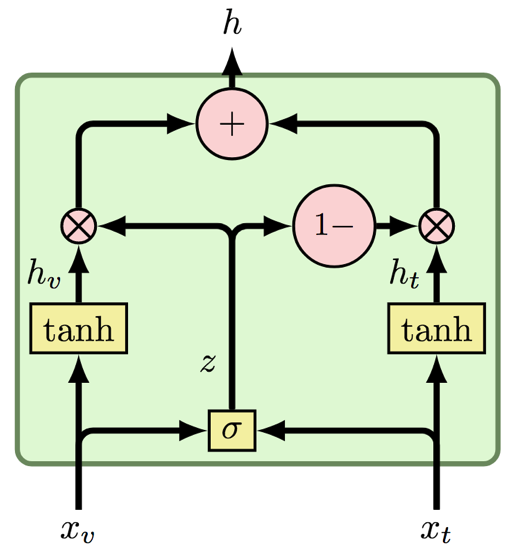
|
where the superscripts \(a\) and \(t\) denote audio and text, \(x\) is the input vector from each modality, and \(\mathrm{W}_*\) and \(b_*\) are parameters. The idea is to let the model decide with the \(z\) vector which modality to allow to pass. Maybe just acoustics, maybe just text, or maybe a bit of both. Then, the resulting representation \(h\) is the sum of the weighted vectors \(h_a\) and \(h_t\), which filter out non-informative aspects from each modality. We will see later how important and insightful is this fusion technique in the visualization discussion.
Global attention
While fusing modalities at the word level is important to enhance word representations, some words are still not relevant for the emotion recognition task. For exmaple, stopwords won’t add much to the overall emotion. This motivates us to add an attention layer at the utterance level. We use multiplicative attention [2] as follows:
\[\begin{equation} \begin{split} e_i =&~ v^\intercal ~\mathrm{tanh}(\mathrm{W}_h h_i + b_h) \notag\\ a_i =&~ \frac{\mathrm{exp}(e_i)}{\sum^{N}_{j=1}\mathrm{exp}(e_j)}, ~~~\text{where}~\sum_{i=1}^N a_i = 1 \notag\\ z =&~ \sum_{i=1}^N a_i h_i \notag \end{split} \end{equation}\]where \(h_i\) is the bimodal representation of the \(i\)-th word (i.e., the output of the GMU cell), and \(\mathrm{W}_h\), \(b_h\), and \(v^\intercal\) are parameters. The final output is \(z\), which is the weighted sum of all the words in the utterance.
Overall model
We have all the components of the model now, which we can visulalize in the following diagram:
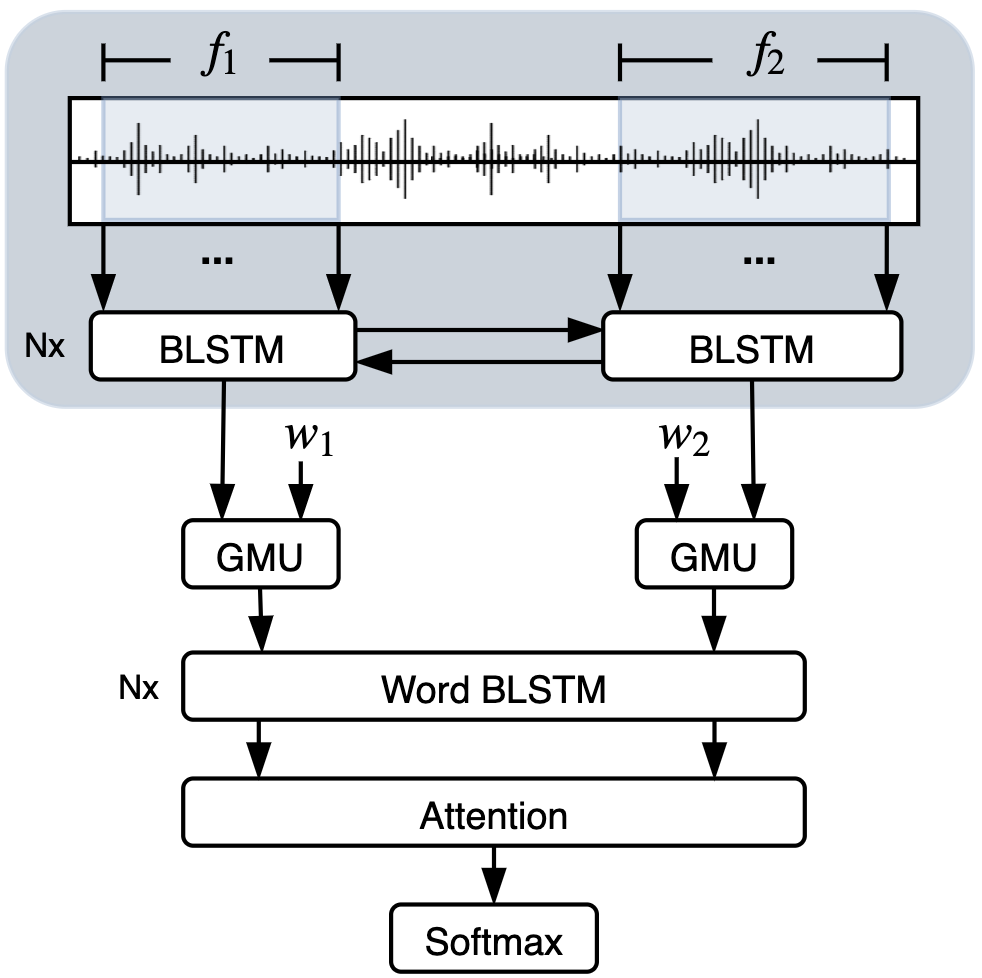
The shadow box at the top of the the figure denotes the acoustic word module, where the inputs are the frame features from the audio. \(w_{1,2}\) are the words from the transcripts of the audios, and they are represented by contextualized vectors from ELMo [3]. Both the modalities are fused in the GMU cell and passed to a bidirectional LSTM followed by the attention layer. We optimized the model by minimizing the negative log-likelihood loss function (other training details can be found in the paper).
Results
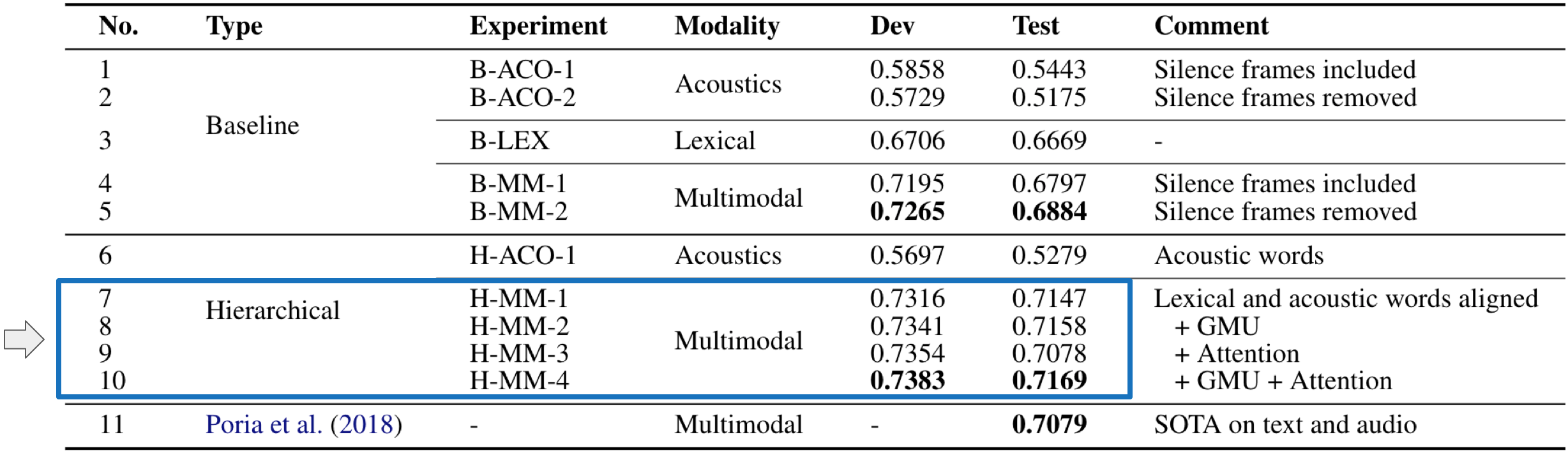
Let’s focus on the highlighted box from the table, which shows to the hierarchical multimodal models (see the paper for other details). These experiments use both acoustics and lexical information, and you can think of row 7 as the baseline because it simply fuses modalities by concatenation and does not have global attention. As you can see in rows 8 and 9, by adding the attention mechanisms, either the word or utterance level attentions, the model improves over row 7. The best results are given by combining both attention mechanisms in row 10. These results align with the intuition that
- although modalities are complementary, sometimes one modality can carry more information than the other, and
- words along the utterance are not equally important.
We can actually see what the model captures in its attention mechanisms in the following predictions:

|

|
|
|

|
The blue and red bars above every word denote the acoustic and lexical information that the model is letting flow through the layers. The bars add up to 1 for every word, and the higher the bar is the more information of that modality is being considered for that word. If you read and then play the examples, you will sense that the acoustic information is essential in the first one, whereas in the second one is more supportive to what is already described by the language. This is precisely what the model is capturing: blue bars are higher in the first example, whereas in the second example red bars can be more informative in some parts of the utterance while still other parts rely better on acoustics (e.g., the beginning of the utterance).
That’s at the word level, but the model also considers filtering out at the utterance level. We can see the probability mass from the global attention distributed along the words of the utterance based on the background color. Note that some words are pretty much ignored leaving the emotion signal on few words. It’s worth mentioning that when only text is used, the behavior of the model changes, and different words are highlighted. This supports the intuition that acoustics and language are complementary and one help the other to be more accurate.
Conclusion
This post briefly covers the first part of our paper “Multimodal and Multi-view Models for Emotion Recognition,” giving more intuition behind the technical decisions and presenting the content in a more friendly manner. Let me know in the comments if you have any questions or suggestions, I will be happy to address them. Thanks for reading!
References
[1] Arevalo et al., 2017. Gated Multimodal Units for Information Fusion.
[2] Bahdanau et al., 2015. Neural Machine Translation by Jointly Learning to Align and Translate.
[3] Peters et al., 2018. Deep Contextualized Word Representations.